AWS S3
Overview
Unit allows its clients access to their raw data, so that they can build their own reporting solutions and make informed business decisions. This integration provides a daily upload into the client's bucket. You can pull the data into your own data warehouse easily with existing connectors, eliminating the need to build a sequence of API calls to obtain data.
The data is structured in a way that makes it easy to do robust analysis on any part of the banking offering. Additionally for companies who are able to securely store personally identifiable information, KYC information can be securely transferred.
By accessing the raw data and creating your own analytics stack on top of it, decision makers in your organization can make data driven decisions on various areas. Some questions that can be looked at include:
- Which end-customer cohorts and/or marketing campaigns created the highest revenue?
- How does pricing (interest, payment fees and rewards programs) affect engagement?
- Which end-customers are most engaged and deserve to be promoted to your "VIP" terms? (example: higher cash-back)
- Which merchants do your end-customers spend most on?
- How do different end-customers segments use ACH, wire and check deposits differently?
The data transferred includes the following data related to ordinary and special bank accounts :
- Authorization Requests
- Payments
- Applications
- Cards
- Counterparties
- Disputes
- Authorizations
- Customers
- Check deposits
- Transactions
- Accounts
Respectively, each bucket will contain any of these folders, while folders that don't contain data will be suffixed with _$folder$ (for example check_deposits_$folder$).
Each of the above folders will contain more folders with the format year_month=yyyy-mm (for example year_month=2021-04/).Each of these folders will contain one or more Parquet files, each containing a portion of the data.
Most Data pipelines frameworks (e.g Fivetran) allow consuming data from the bucket very easily.
If you’re interested in accessing your data with this integration, contact Unit to get it enabled and set up.
Data transfers occur twice a day:
7 a.m. UTC with data that was created up until 04:00 a.m.
3 p.m. UTC with data that was created up until 12:00 p.m.
Prerequisites
- Active Organization in Unit
- Active AWS S3 bucket in us-east-1 region
- Admin privileges
Configuring your S3 Bucket
After you have created an S3 bucket and sent its details to Unit and received a role in return, Follow the following steps in order to provide Unit with access permissions to your S3 bucket. Once this is set, Unit will transfer your data to the chosen bucket daily.
- Sign in to the AWS Management Console and open the Amazon S3 console.
- In the Buckets list, choose the name of the bucket that you want to create a bucket policy for, or whose bucket policy you want to edit. The bucket can be located in any region.
- Choose Permissions.
- Under Bucket policy, choose Edit. This opens the Edit bucket policy page.
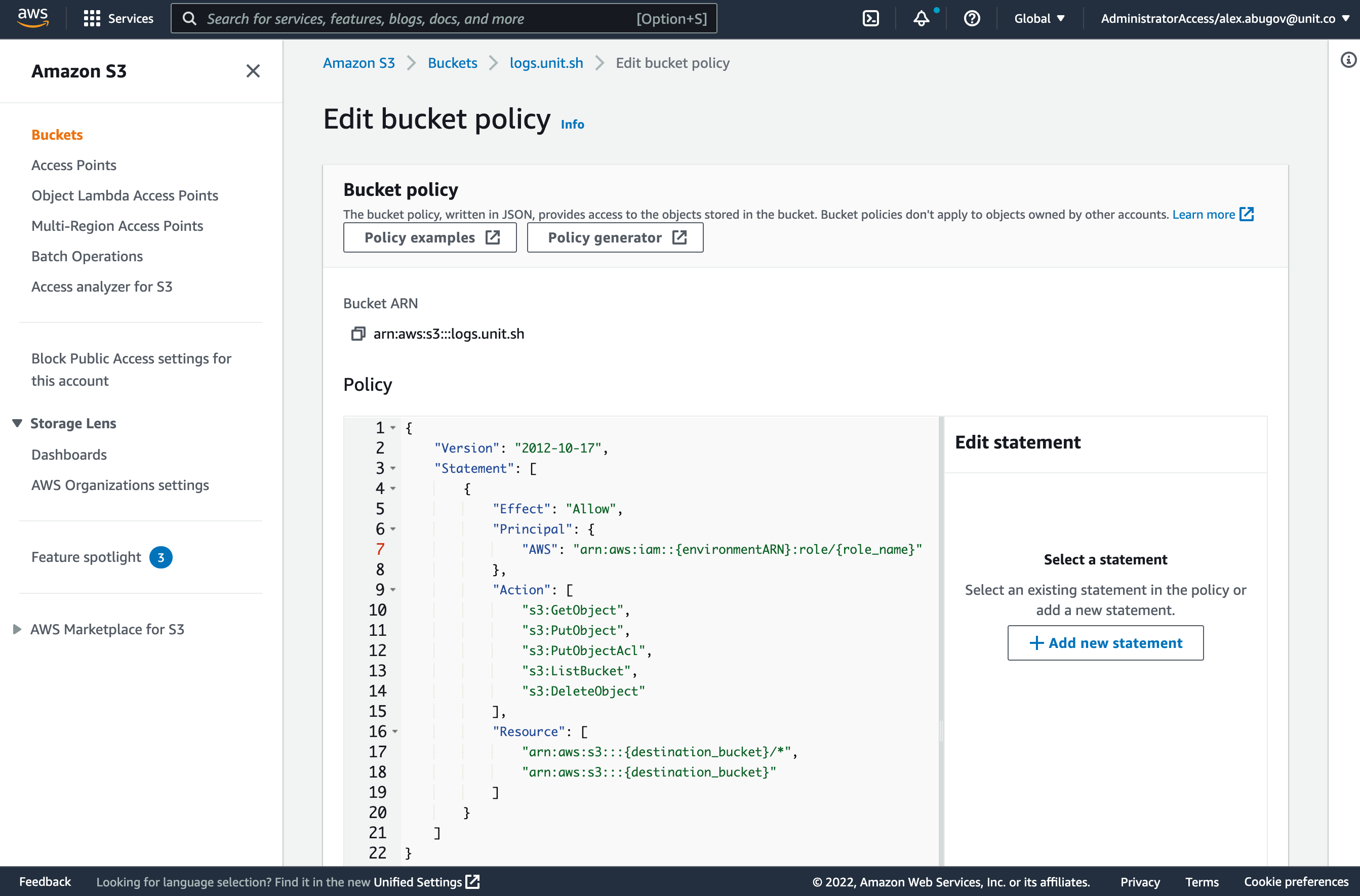
- In the Policy box, paste the following bucket policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{environmentARN}:role/{role_name}"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::{destination_bucket}/*",
"arn:aws:s3:::{destination_bucket}"
]
}
]
}
Change the
{environmentARN}to the suitable value according to the following table:Environment Amazon Resource Name Sandbox 428821834064 Live 085438893023 Change
{role_name}to the role of the specific organization:glue-unit_yourcompany_etl_job-role.Change
{destination_bucket}to the name of your S3 bucket.Choose Save changes.
Enable “Bucket Owner enforced” at the bucket level: